LlamaIndex
public: 2025-04-19
See also the main item: /LLM.
类似/相关: haystack
ref: LlamaIndex 原理与应用简介(不同场景下的架构逻辑) by bilibili 字节字节
LlamaIndex 的核心功能 #
知识库问答示例
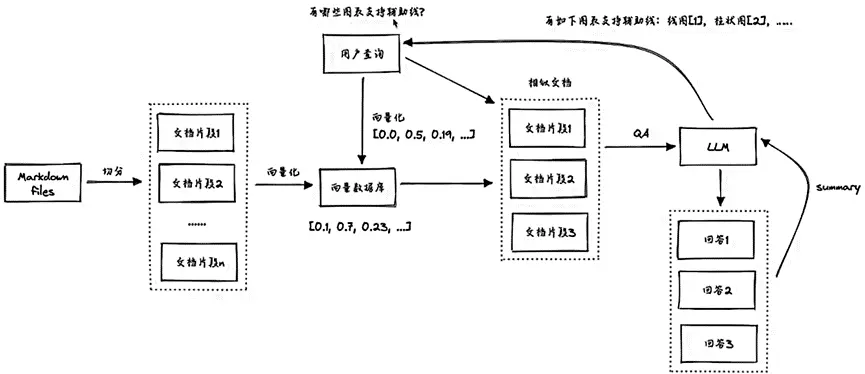
- 总体流程:
- 载入数据,切分
- 构建 index
- ·持久化 index
- ·查询与生成
- Data connectors:APIs,pdf,ppt,docx,markdown,image,audio,video,tables…
- Index:list,vector store,tree,keyword table,Pandas,SQL
- 存储,与各类向量数据库的对接。0.6 版本之后更加复杂,分成 doc,indexi 和 vector3 三块存储
- Query:.各种对应 index 的查询与结果生成,主要分成 retrieve(召回)和 synthesize(整合生成)两部分
- Query 结果中的 extra_info,支持引用展示
- Post process:召回的“后处理”,例如关键词过滤,重排序等
- 定制化,包括 LLM,prompt,embedding,存储等
- Optimizers,优化调用,节省 token
与 Query 相关的特性与场景 #
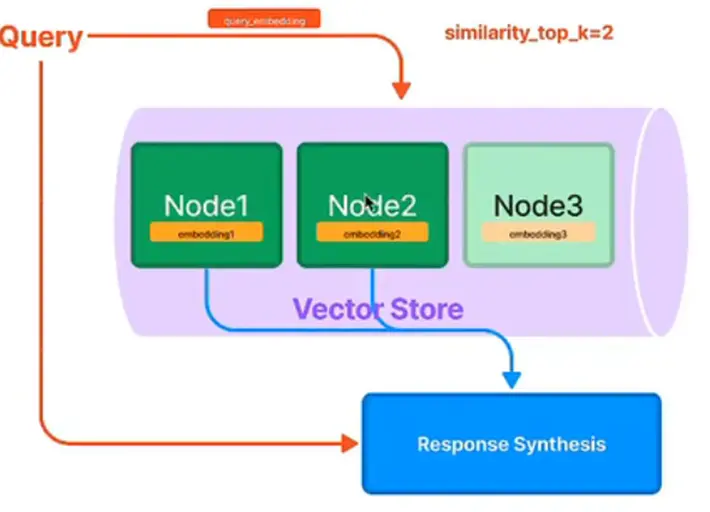
Vector Index - 常用于 QA #
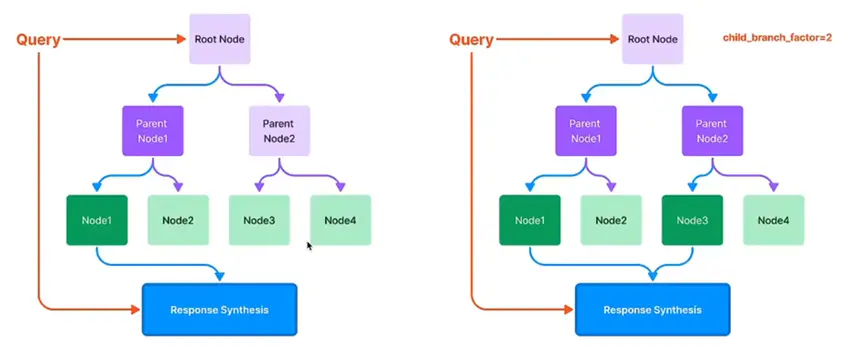
Tree Index - 多个知识库的场景(自底向上用 Prompt & synthesis 的方法递归生成 parent nodes) #
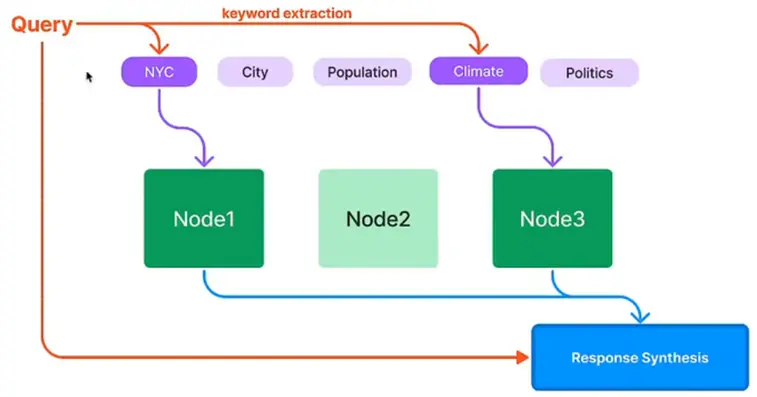
Keyword Table Index - 常用于问题比较短,有很多专有词的场景(Keywords 也是通过 prompt 生成) #
DEFAULT_KEYWORD_EXTRACT_TEMPLATE_TMPL = (
"Some text is provided below.Given the text,extract up to {max_keywords}"
"keywords from the text.Avoid stopwords."
"-------------------------------\n"
"{text}\n"
"-------------------------------\n"
"Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'\n"
)
DEFAULT_KEYWORD_EXTRACT_TEMPLATE KeywordExtractPrompt(
DEFAULT_KEYWORD_EXTRACT_TEMPLATE_TMPL
)
# NOTE:the keyword extraction for queries can be the same as the one used to build the index,but here we tune it to see if performance is better.
DEFAULT_QUERY_KEYWORD_EXTRACT_TEMPLATE_TMPL = (
"A question is provided below.Given the question,extract up to {max_keywords}"
"keywords from the text.Focus on extracting the keywords that we can use
"to best lookup answers to the question.Avoid stopwords.\n"
"-------------------------------\n"
"{question}\n"
"-------------------------------\n"
"Provide keywords in the following comma-separated format:'KEYWORDS:<keywords>'\n"
)
DEFAULT_QUERY_KEYWORD_EXTRACT_TEMPLATE = QueryKeywordExtractPrompt(
DEFAULT_QUERY_KEYWORD_EXTRACT_TEMPLATE_TMPL
)
Structuring Data #
- 非结构化数据转化为结构化数据 (从非结构数据构建结构化 index)
- 构建 table
- 输入非结构化文档
- 转化后将数据存入 table
- Text to SQL with context
- Index for table context, 把整个数据库的 table schema 都 index 起来
- 找到和 Question 最接近的 table 表,然后把 Q 和 table 结合生成回答 Ans。
def derive_index_from_context(
self,
index_cls:Type[BaseGPTIndex],
ignore_db_schema:bool False,
**index_kwargs:Any,
) → BaseGPTIndex:
"""Derive index from context."""
full_context_dict self._get_context_dict(ignore_db_schema)
context_docs = [
for table_name,context_str in full_context_dict.items():
doc Document(context_str, extra_info={"table_name": table_name})
context_docs.append(doc)
index = index_cls.from_documents(
documents=context_docs,
**index_kwargs,
return index
Query Transformer #
情况 1 #
Query 比较短,容易导致 embedding 搜索结果不理想。解决方案可以是 HyDE:先让模型在不查资料的情况下做个回答,把此回答和原问题一起扔进去(相当于丰富了原问题/Prompt)做向量化检索。
情况 2 #
情况 2.1,Query 中,要比较两个文档中的两个 entity,需要先对两个文档单独分析在进行比较。
情况 2.2,问题“跨库”(???),例如“关于第一个登月的人,今年有什么新闻和他相关”。解决方案可以是步骤拆解 Decompose,包括单步拆解和多步拆解。
单步拆解(e.g. 比较来自两个文档的两个 entity, 并行执行,都是单步)
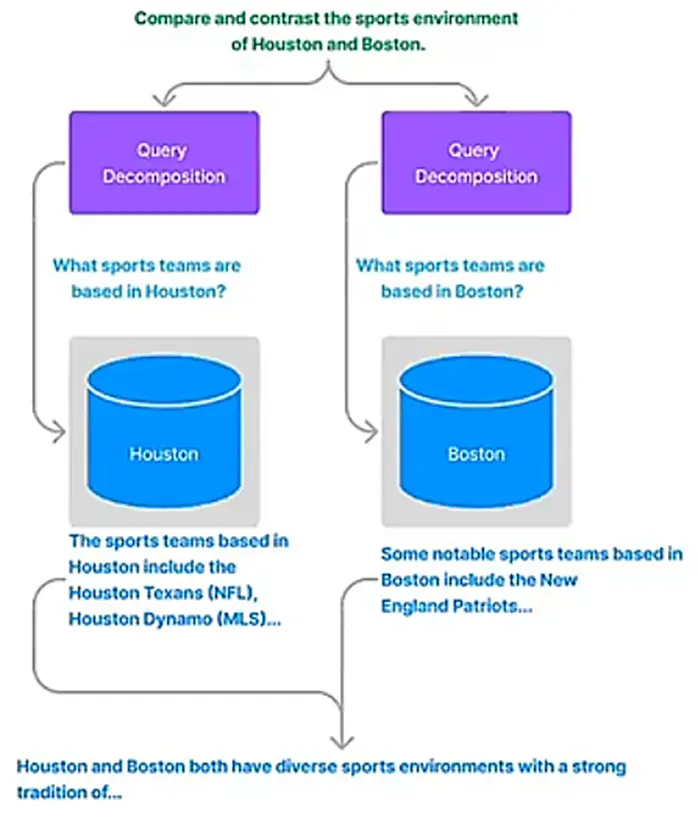
# Setting: a list index composed over multiple vector indices
# ilm_predictor_chatgpt corresponds to the ChatGPT LLM interface
from llama_index.indices.query.query transform.base import DecomposeQueryTransfo
decompose_transform = DecomposeQueryTransform(
llm_predictor_chatgpt,verbose=True
)
# initialize indexes and graph
...
# configure retrievers
vector_query_engine = vector_index.as_query_engine()
vector_query_engine = TransformQueryEngine(
vector_query_engine,
query_transform=decompose_transform
transform_extra_info=('index_summary':vector_index.index_struct.summary)
custom_query_engines = (
vector_index.index_id:vector_query_engine
)
# query
query_str = (
"Compare and contrast the airports in Seattle,Houston,and Toronto."
)
query_engine = graph.as_query_engine(custom_query_engines=custom_query_engines)
response = query_engine.query(query_str)
多步拆解: 把问题拆分成几个步骤,一步一步接近答案。 e.g. 第一个登月的是 Amstrong, Amstrong 生于 xx 年,所以他今年 xx 岁。
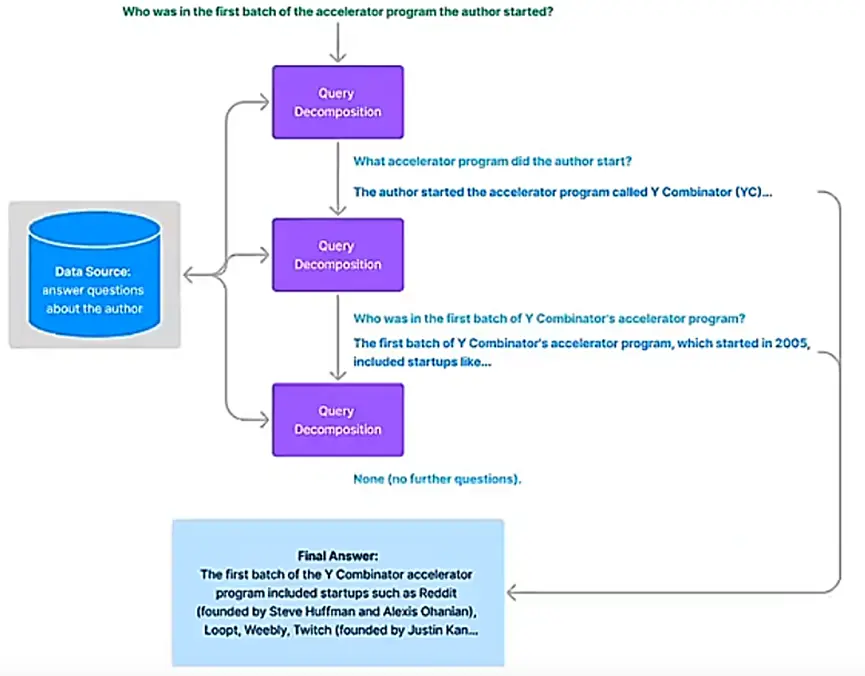
与 Answer 生成相关的特性与场景 #
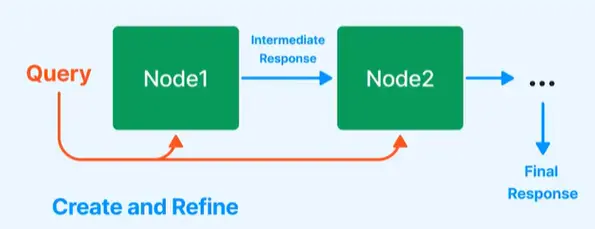
Compact & Refine (串行, 默认的答案生成方式) #
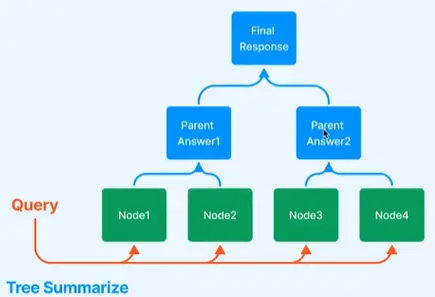
Tree Summarize (并行) #
e.g. 帮我找最近的 5 篇 AIGC 文章并总结。
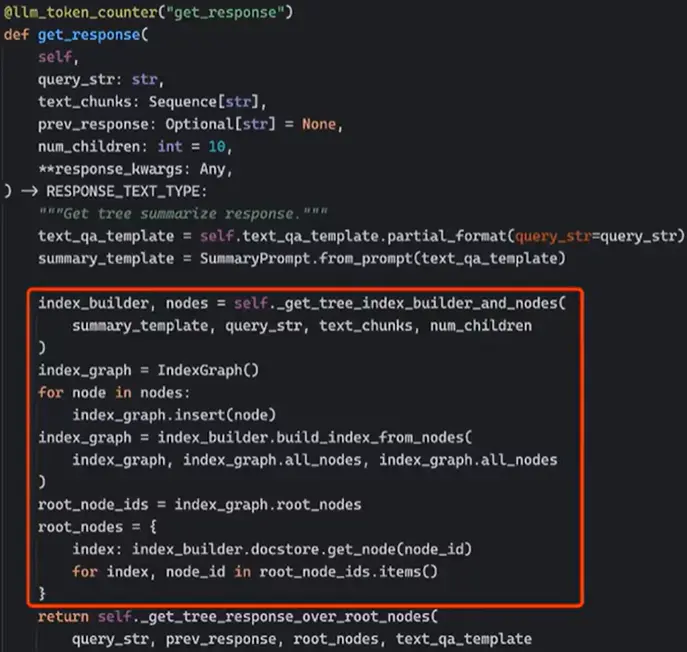
Composibility (串并行各种组合) #
- Index 可以嵌套,类似的,Query Engine 也可以定制组合 (串并行组合)
- 父查询为入口,触发 retrieve
- 子查询完成 retrieve+synthesize
- 父查询再做 synthesize
- LangChain 可以把 LlamaIndex 作为工具来调用
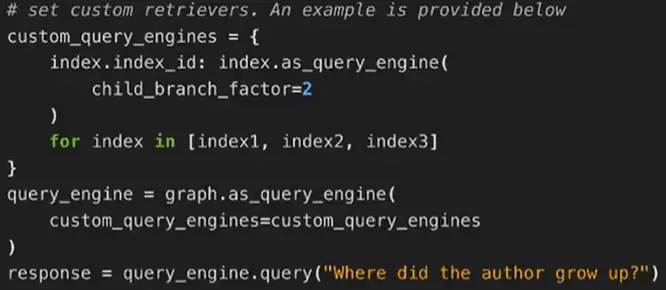
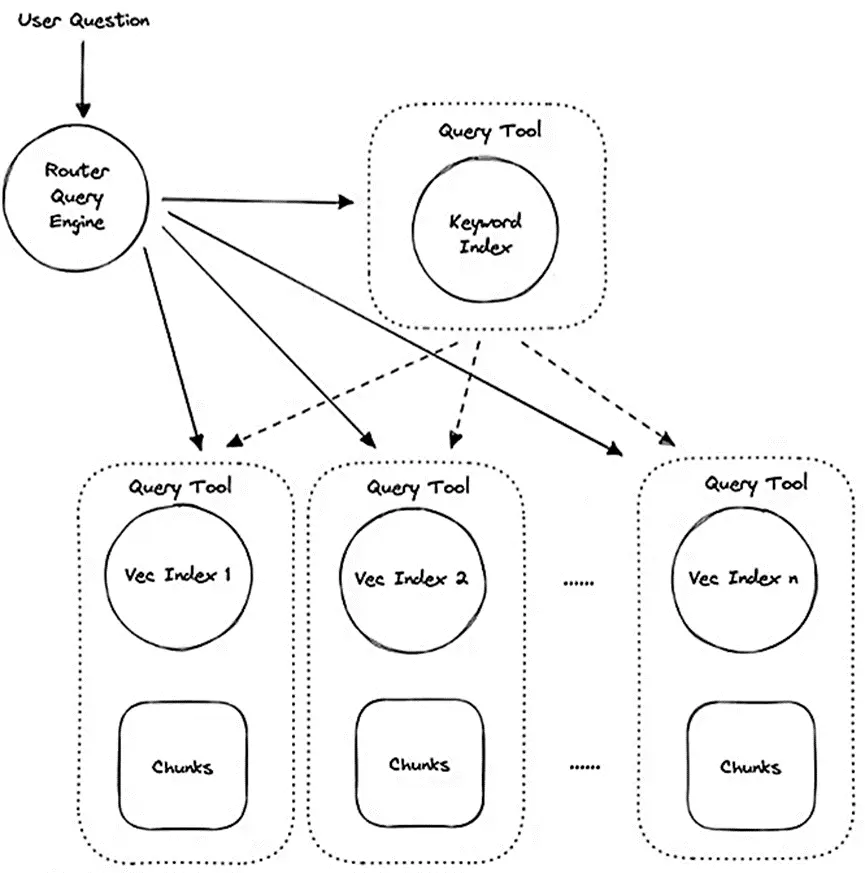
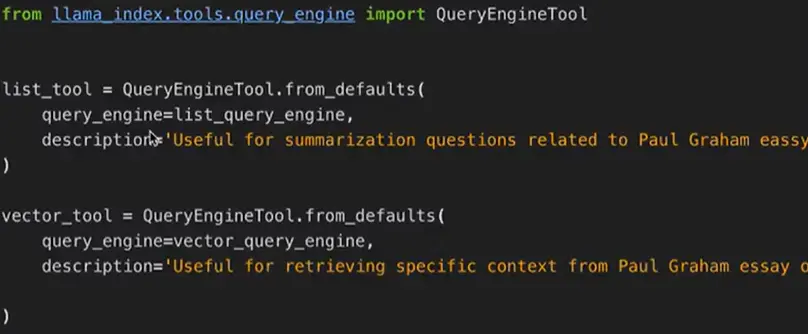
Route Retriever (复杂串并联时,可以选择走哪条路) #
- 多套 index, 动态选择应该查询哪个 index
- 类似 LangChain 里 tool 的概念
- 可以做出非常复杂的路由配置
AutoGPT #
相当于 GPT + 插件。 类似项目:BabyAGI。
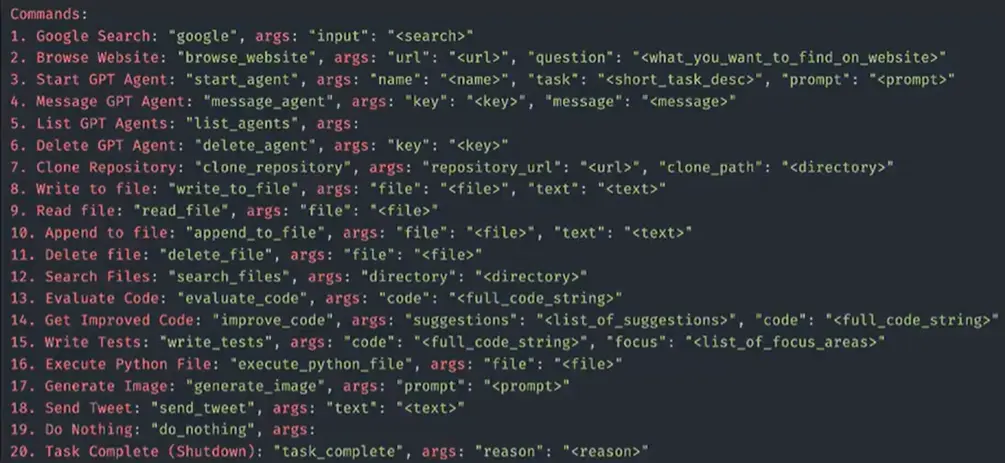
主要贡献/特点:
- 提出可以使用工具集(20+ 种工具)的 agent
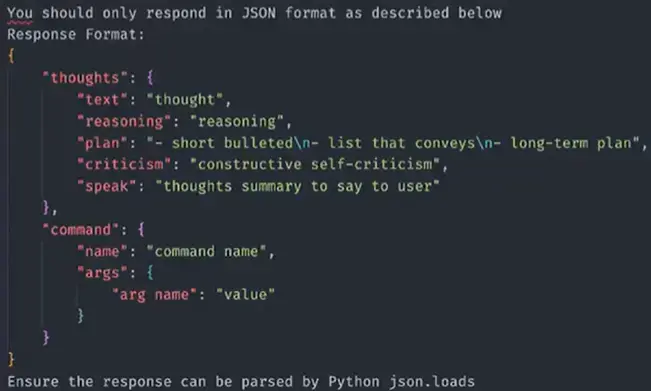
- 设计了含有多种技巧的、大的、复杂的 Prompt
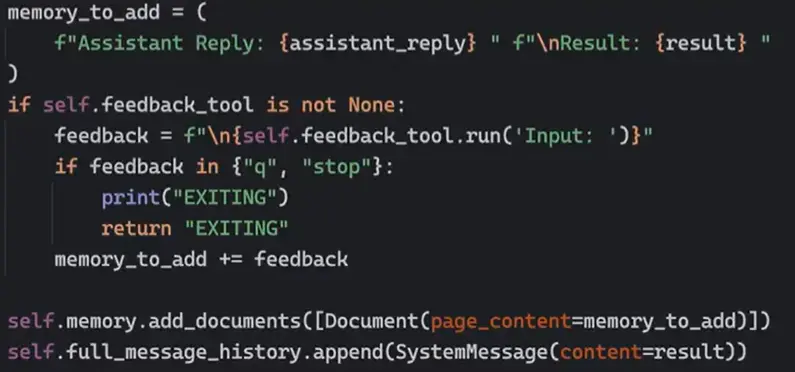
- 带有记忆的 agent
- 计算 importance (优先级)并排序 (向量 relavance 相对比较好算)
- 自动 planning
- 可以人工干预
例如:
工具集:
agent 记忆 document:
复杂的 Prompt
主要问题:错误累积 (串连,一步错步步错);费 token。
减少错误方法 1: 引导单个 agent“自我反省”几次。
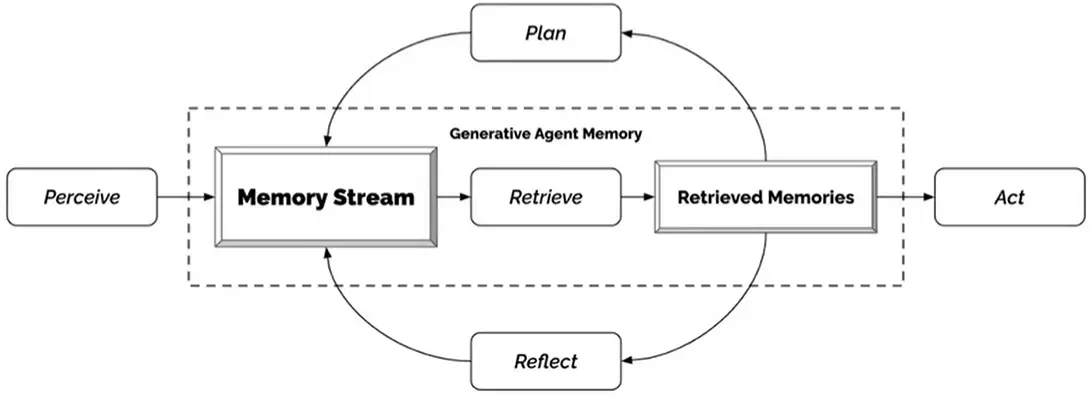

减少错误方法 2: 多个 agents (Multiple Agent) 各自从事自己擅长的工作。 代表工作: Camel (by 阿卜杜拉国王大学): 一个业务专家,一个代码专家,协作完成任务。
Prompt 范式 #
- Chain of Thoughts, 把步骤列出来。
- 自我审视,让模型多想一想。Anthropici 还用这招来替代 RLHF.
- 分而治之,把任务拆分,通过多次 LLM 调用/外部工具/单独的 gent 来完成一个个子任务。
- 先计划,后执行。分而治之除了由人工拆分,也可以让模型自己做计划拆分。
- 融合记忆系统,包括 prompt 里的短期记忆,外部存储的长期记忆等。
- 结构化输出,例如 json 等。
- Ensemble (让 agent 多重复几次), 提升稳定性。
